In Full...
Programming note: Technical Chops is back from the August break. From this week on, posts will be delivered on a Friday morning.
One of the challenges with Large Language Models (LLMs) is that they are still, quite often, incorrect. Worse still, they are confidently incorrect. They are, to put it politely, bullshitters.
Software in Critical Environments
Within a critical environment, we build in a way which assumes that software, or the hardware that runs or is an input to that software, can be wrong.
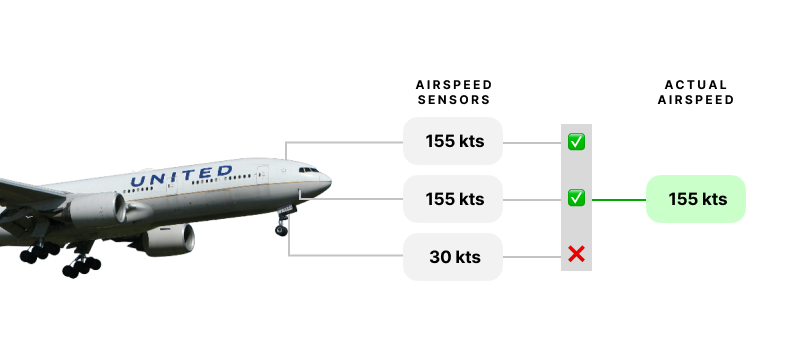
Airliners are an acute example – they don’t just have one sensor for a given metric, they often have at least three. By using the data from three sensors, their software can use a methodology called Triple Modular Redundancy (TMR) to identify when one of the sensors is providing bad data. If one airspeed sensor starts saying that the plane is going too slowly, but the other two sensors say everything is normal, TMR allows the plane to effectively take the “votes” of the two normal sensors as the correct speed. This is especially critical when the plane can take actions by itself based on those inputs; the lack of it was a contributory factor to the Boeing 737 Max disasters in 2018 and 2019.
Thankfully, I can’t think of any good uses for LLMs in critical environments. Whilst there have been cases where lawyers have cited fake cases created by ChatGPT and faced the resultant wrath of a judge, most of the time the stakes are your own, or your product’s, credibility.
Most people like protecting their credibility though, and so there are use cases which would be perfect for an LLM but which we tend to avoid implementing because of the risk of the AI hallucinating an answer.
Learning from critical environments
We tend not to implement TMR in environments where it’s not strictly necessary. It’s an unnecessary overhead, in terms of maintenance, complexity and of course cost. Most of the time, properly written software will do exactly what it is supposed to do, with bugs and edge cases more of a curiosity that are easily solved once identified.
The issue with LLM hallucinations though is that we can’t “solve” them. And they happen inconsistently, precisely because of the way that LLMs work. If you ask the same LLM the same question phrased in slightly different ways, you will still get varying answers.
One way we try to get better results from a model is by “fine-tuning” a model. This means that a model is trained on specific content or a use-case so that it better understands what it needs to do. This is quite often costly, but it does work well, right up until the point that a new frontier model is produced that outperforms the fine-tuned model. At that point the investment made into the fine-tuned model is nullified because it makes more sense to switch to the outperforming model.
Making use of TMR in LLMs
The cost of LLMs has plummeted over the past two years. Standing at around $2 per 100,000 words1, we’re now in the realm that for any decent business use-case, model costs aren’t a huge consideration.
What if we used three (or more) different models simultaneously and provided them with the same query, and then allowed them to vote on the best answer? Perhaps implementing a form of TMR could solve the problem of inaccuracy within LLMs.
Well, the only way to find out is to actually do it: https://consensus.technicalchops.com/basic
I’ve kept it simple, but the concept is pretty straight forward: Ask a question and GPT-4o, Claude 3.5 Sonnet and Google Gemini 1.5 Pro will all provide an answer. Those answers are then fed back into the same models (without previous context) and the models are asked to vote for the best answer.
We can take this a step further though. What if we allow the models to correct each other’s work prior to choosing the best optimised answer? The results is that we do tend to get better answers. You can give the optimised version a go here: https://consensus.technicalchops.com/optimise
The delay in the response is noticeable, but I think the idea has the possibility to improve accuracy when using off the shelf LLMs2 and, vitally, to catch the mistakes that cause us to distrust them.
The code is available here: https://github.com/simonminton/consensus-article